What is Subquery?
To put it simply, subquery is a query nested in another query. The outer query is referred to as the main query while the inner query is the subquery. So, a subquery is the inner query of the main query. It is usually embedded in the WHERE clause of the main query.
What is Correlated Sub Query
Correlated sub query is a type of subquery which uses the value of the outer query in the inner query. The outer query (main query) depends or relies on the result of the inner query (subquery). For every record of the main query, the subquery is evaluated once.
correlated subquery is also known as synchronised subquery due to the way it operates.
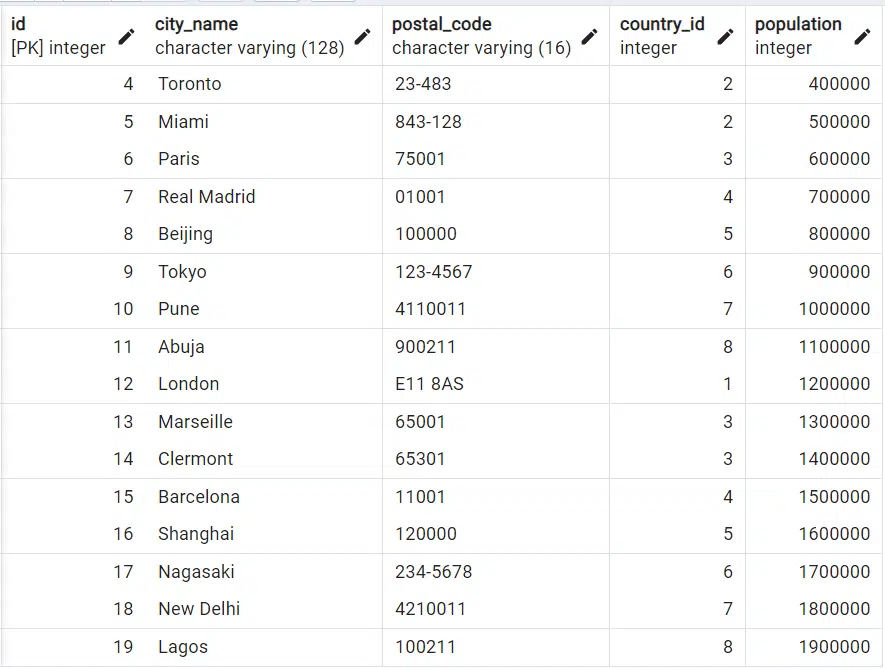
Imagine you have a table called city. The table has a population column with null data. As an example, you can populate the table using the following subquery.
UPDATE city c1
SET population = (SELECT 100000 * id from city c2 WHERE c1.id = c2.id)
In the query above, you can see I am updating the population column for all the records in the table. This is achieved using the correlated subquery.
c1 is the alias of the outer table while c2 is the alias of the inner table. Now, the subquery will be evaluated once for each record in the outer table.
For the first record, based on the subquery condition, it’s going to check if the id of the outer table is equal to the id of the inner table. Take the first record for example, the query will check if the inner table has an id of 3. Since this is true, according to the query, it will set the population to 100000 * 3. The result will be 300000, as you can see in the table below. This will be the same process for all the records in the table.

Correlated Subquery Using Not Exists Operator
If you want to return the record of city with the highest population, you can use the following correlated subquery to achieve that.
SELECT * FROM city c1 WHERE NOT EXISTS(
SELECT * FROM city c2 WHERE c2.population > c1.population
)
What the above query does is find the city population such that other city population which is greater does not exist. In our case 1900000 is the population. 1900000 is the population in the subquery in which the other city (in this case, we are checking c2 table) population cannot be greater than.
Let dive into how the query works in details so you can have a better understanding of the purpose of the NOT EXISTS operator.
Based on the definition of correlated subquery, we need to evaluate the inner query once for each record of the main query.
Now using the above city table, Birmingham has a population of 300000. The inner query has a condition (WHERE c2.population > c1.population). Let check where the population in table 2 (c2) is greater than 300000. If we check, we can see the first output is false since 300000 is not greater than 300000. However, the second check will return true since 400000 (Toronto population) is greater than 300000. Since the condition return true in the second record check of first iteration, the condition is not satisfied. So, the next iteration will start.
Since the first iteration is done for the first record, the second iteration will start for the second record of the outer table c1. In this case, the inner query will be evaluated for the Toronto population (400000). It will check if 300000 > 400000. The result is false, which satisfy the condition. It then check if 400000 > 400000. The result is also false. It keeps checking until all the output are all false for the specific population. If the check return true, then it moves to the next iteration.
Below is the result of the query.

How Correlated Subquery Works
For better understanding, below is how the subquery operates under the hood.
Iteration 1 : does not return all false – condition is not satisfied.
c2.population c1.population
300000 > 300000 -> false
400000 > 300000 -> true
Iteration 2: does not return all false – condition is not satisfied.
c2.population c1.population
300000 > 400000 -> false
400000 > 400000 -> false
500000 > 400000 -> true
Iteration 3: does not return all false – condition is not satisfied.
c2.population c1.population
300000 > 500000 -> false
400000 > 500000 -> false
500000 > 500000 -> false
600000 > 500000 -> true
Iteration n: does not return all false – condition is not satisfied
Iteration 17: return false for all records – satisfies condition
c2.population c1.population
300000 > 1900000 -> false
400000 > 1900000 -> false
… > … -> false
1900000 > 1900000 -> false
Now, let’s say we want to find the city with the lowest population, we would use the same approach above and write the following subquery.
SELECT * FROM city c1 WHERE NOT EXISTS(
SELECT * FROM city c2 WHERE c2.population < c1.population
)

You can see the NOT EXISTS operator return the record when the condition of the inner query returns false for all of its check.
Subquery Using Exists Operator
On the other hand, the EXISTS operator return the record when the condition is true. Say for example, we want to return all the records except the minimum record, we can write the follow correlated subquery.
SELECT * FROM city c1 WHERE EXISTS(
SELECT * FROM city c2 WHERE c2.population < c1.population
)
Scalar Subquery
One other type of subquery I want to talk about is the scalar subquery. This type of subquery return just one record or value or one column.
Now using the table above, let’s say you want to select or return cities that have their population greater than the average population of the overall cities in the table, you can use subquery to do that.
Below is the subquery that will give you the correct result.
SELECT * FROM city WHERE population > (SELECT AVG(population) FROM city)

The inner query (SELECT AVG(population) FROM city) is scalar since it only returns the average population.
















